
cs231n study note 1
一、学习内容
- Data Driven Approach 数据驱动的方法
- KNN K最近邻算法
- Linear classifiers 线性分类器
- Loss function 损失函数
- Optimization 优化
- Back propagation 反向传播
- Neural Networks 神经网络
1. 数据驱动
1.1 思路
dataset: labels –> train –> predict
1.2 CIFAR-10数据集
该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。

Data
1
2一个10000*3072的numpy数组, 数据类型是无符号整形uint8. 这个数组的每一行存储了32*32大小的彩色图像(32*32*3通道=3072).
按1024分组, 分别是red,green,blue通道. 图像是以行的顺序存储, 即前32个数是该图的像素矩阵的第一行.Labels
1
一个范围在0-9的含有10000个数的列表(一维的数组)。第i个数就是第i个图像的类标.
2. K最近邻算法
- 分类器中最简单的例子
- 在dataset中寻找与input最相似的
2.1 L1 distance / Manhatton distance
2.2 复杂度分析
Train – O(1)
Predict – O(n)结论: 不理想 (VS CNN)
2.3 图像之间的视觉判断
不同的图片, 使用KNN可以得到的结论是相同 PS某种情况下也是优势
2.4 维度灾难
随着维度的上升, 复杂度指数级增长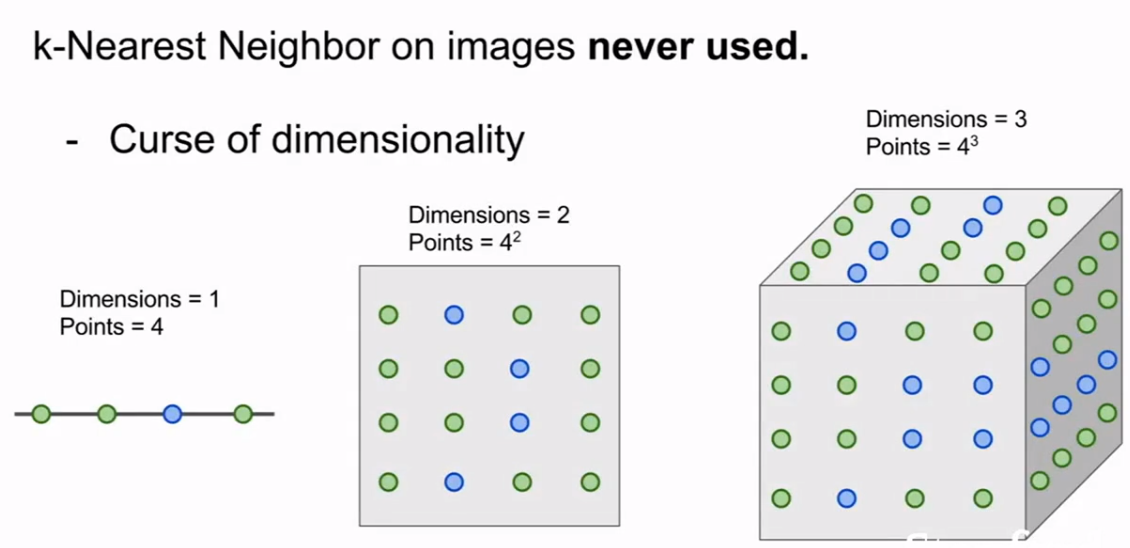
3. 线性分类器
3.1 参数模型中最简单的实例
3.2 简单表达式:
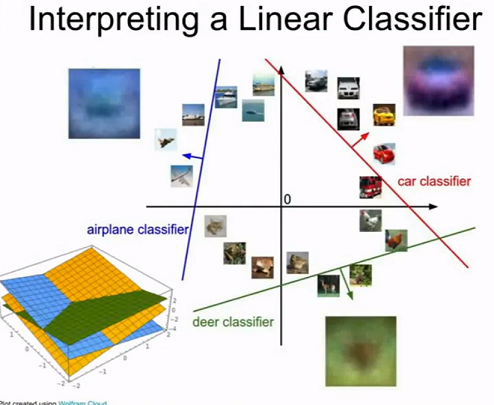
3.3 示例图
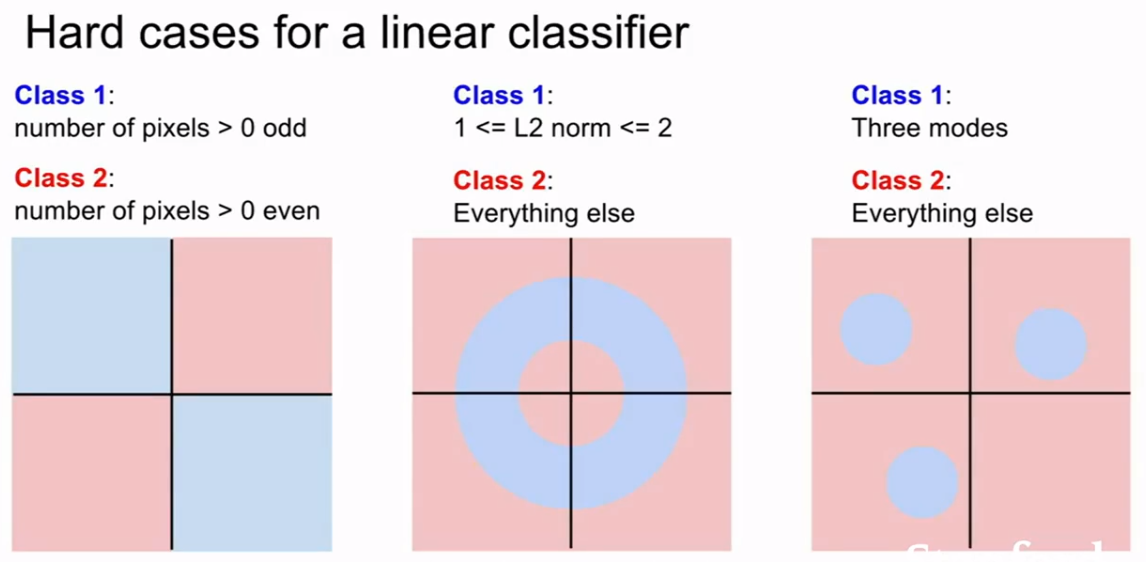
3.4 线性分类器的劣势
3.4 两种解释方法
- 每个种类的学习模板
- 学习像素在高纬度空间的一个线性决策边界
4. 损失函数
- dataset.
目的是寻找一个合适的W, 使得L最小find:
4.1 multiclass SVN loss
- 如果求和中不排除相当的情况, 则L++
- 使得L=0(L最小)的情况的W并不唯一, exp:2W
- 如何在诸多使得L=0的W中选择最合适的
- 最简约
- 奥卡姆剃须刀
- Regularization: model should be simple so it works on test data
- 正则化
- R(W)分类
- L2 ==>
- L1 ==>
- Elastic net (L1+L2)
- Max norm
- Dropout
4.2 multinormial logistic regression
多项逻辑斯蒂回归
softmax loss

5. 优化
5.1 梯度下降 Gradient Descent
1 | while true: |
step_size 步长 学习率 超参数 优化第一步
5.2 Stochastic Gradient Descent(SGD)
随机 minibatch小批量 蒙特卡洛估计
- 数值计算 – 反向传播
- 解析计算
6. 反向传播
6.1 导数/梯度过于复杂无法计算
6.2 链式法则
6.3 计算图
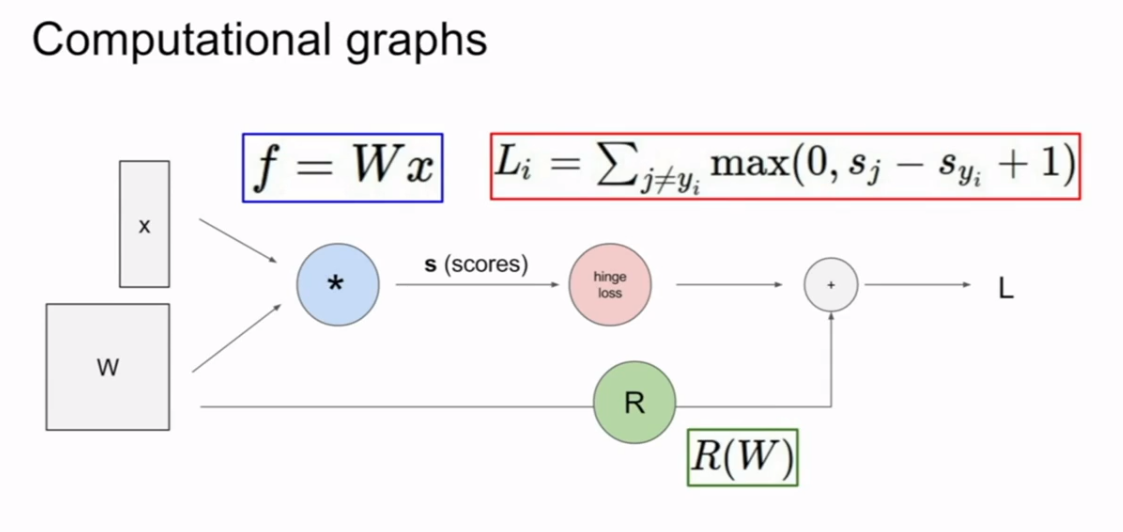
6.4 例证
VS

6.5 向量-雅可比矩阵
7. 神经网络初步
多阶段分层计算
多个W
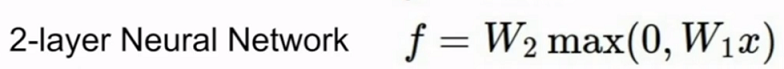

###层数叠加 – deep xxx
###activation function(类比神经元)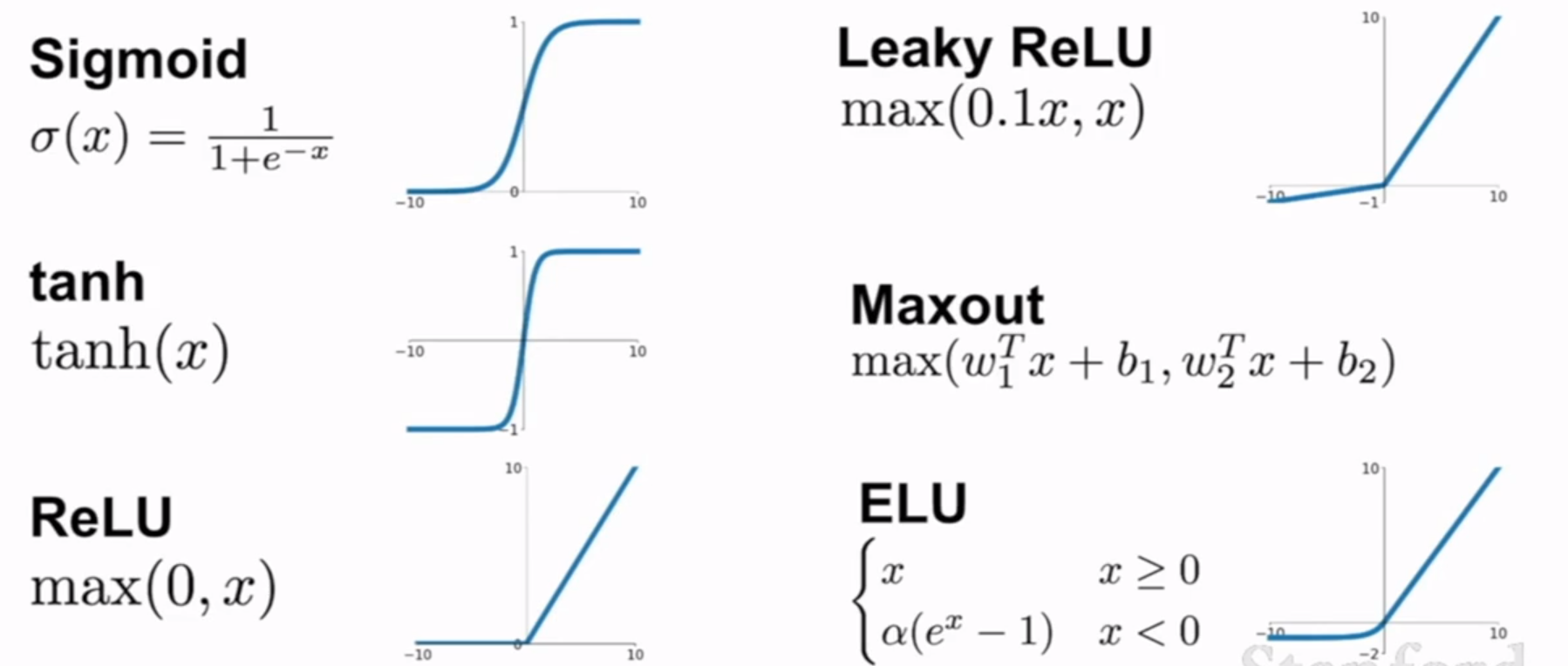
###neural networks architectures
code
1 | class Neuron: |
二、工作相关
1 | 使用了python对每个帐号的封号进行机器学习 |